Table of Contents
| Kirsh home: Articles: Worldlets: 3D Thumbnails for 3D Browsing |
| This appeared in Proceedings of
the European Cognitive Science Society (1999).
Formal citation: Worldlets: 3D Thumbnails for 3D Browsing. Worldlets: 3D Thumbnails for 3D |
|
Dept. of Cognitive Science
Univ. California, San Diego
La Jolla, CA 92093-0515
+1 858 534-3819
kirsh@ucsd.edu
Abstract
Dramatic advances in 3D Web technologies have recently led to widespread development of virtual world Web browsers and 3D content. A natural question is whether 3D thumbnails can be used to find one's way about such 3D content the way that text and 2D thumbnail images are used to navigate 2D Web content. We have conducted an empirical experiment that shows 3D thumbnails, which we call worldlets, improve traveler's landmark knowledge and expedite wayfinding in virtual environments.
Keywords
3D thumbnails, wayfinding, VRML, virtual reality, empirical study
Introduction
As the Web moves into 3D, the problem of finding one's way to sites of interest is exacerbated. Currently URLs are represented on a page or menu by sentences as in Figure 1, or by 2D thumbnail images which depict some aspect of the URL as in Figure 2. It is reasonable to suppose that 3D thumbnails -- or worldlets -- will soon come into use. To test whether worldlets improve wayfinding we designed a psychological experiment aimed at answering the following questions:
 | ||
| Figure 1. A Web page linking to alternative destinations within a virtual world. On this page, the destinations are represented with text. | ||
• are menus of worldlets better than menus of text and 2D images for wayfinding ?
• what aspects of the wayfinding process are most enhanced by the use of worldlets ?
In the experiment subjects were placed at starting locations in three virtual cities and asked to find their way to goal locations via a series of landmarks. In one city, the landmarks were described with text, in another city the landmarks were described using 2D thumbnail images, and in yet another city the landmarks were described using manipulable worldlets. We hypothesized that, compared to text and thumbnail images, worldlets would facilitate landmark knowledge and expedite wayfinding.
 | ||
| Figure 2. On this Web page, the destinations from Figure 1 are represented as 2D thumbnail images. | ||
Wayfinding
Wayfinding is "the ability to find a way to a particular location in an expedient manner and to recognize the destination when reached" [Peponis90]. To prevent travelers from becoming disoriented and lost, a world must contain useful wayfinding cues. Such cues enable a traveler to build a cognitive map of a region, and thereafter navigate using that map [Lynch60] [Passini92]. A cognitive map is built from survey, procedural, and/or landmark knowledge. Survey knowledge provides a map-like, bird's eye view of a region and contains spatial information including locations, orientations, and sizes of regional features. Procedural knowledge characterizes a region by memorized sequences of actions that construct routes to desired destinations. Landmark knowledge records the visual features of landmarks, including their 3D shape, size, texture, etc. [Appleyard69] [Goldin82].
Although social and engineering scientists have studied human wayfinding in the real world for many years [Lynch60] [Appleyard69] [Goldin82], [Downs73] [Passini92] [Peponis90] [Presson84], only recently have computer scientists investigated this subject. Satalich [Satalich95] led human subjects on a tour of a virtual building and then tested the subjects' ability to find their way to places seen during the tour. Darken [Darken96] applied Lynch's city structure theories [Lynch60] to large sparsely featured virtual environments and then compared subjects' ability to find their way to target destinations with and without the added city structure. Witmer [Witmer96] studied route learning and found that subjects who rehearsed a route in a virtual building learned the route better than subjects who rehearsed the route verbally. Although each of these studies recognized the value of landmark knowledge for wayfinding, none studied the value of landmarks in familiarizing subjects with an environment before entering it.
Virtual cities and landmarks
3D models of large cities are becoming available for exploration via the Web [Liggett95] [Art+Com] [UCL]. The studies just described showed that travelers visiting such large virtual environments for the first time are easily disoriented, may have difficulty identifying a place upon arrival, and may not be able to find their way back to a place just visited.
We hypothesized that by enabling a traveler to become familiar with landmarks before visiting an environment, the traveler will be better prepared to: (1) find their way to destinations of interest, (2) recognize destinations upon arrival, and (3) find their way back to previously visited places. More generally, we believe that directions are more effective if presented using landmarks, and specifically using 3D landmarks. This is in keeping with Wickens claim that virtual environment search tasks are difficult because "often the object of the search is specified in a format different from and more abstract than its rendering in the virtual environment." [Wickens94] Worldlets address this problem by representing the object of the search in the same 3D format as the virtual environment, thereby giving searchers first-person experience with virtual world landmarks.
What are Worldlets
In two previous papers we described our preliminary worldlet design, implementation, and pilot study [Elvins97a] [Elvins97b]. Like a 3D photograph, a worldlet is associated with a viewing position and orientation, and captures a snapshot of the 3D shapes (usually landmarks) falling within the viewpoint's viewing volumes. Worldlets can be explored and manipulated in the same way that virtual worlds can be explored and manipulated. Incorporated into a VRML browser, a guidebook or list of worldlets enables a world traveler to view landmarks and landmark context from multiple vantage points. Seeing the landmarks presented in worldlets may help a traveler select destinations of interest and navigate unfamiliar worlds.
Figure 3 depicts the process of constructing a spherical worldlet from a fragment of a virtual city surrounding a central viewpoint position. Once captured, worldlets can be browsed, manipulated, and explored in a number of ways.
 | ||
| Figure 3. Construction of a worldlet. A virtual city landmark (a) viewed from a vantage point, (b) showing the highlighted region to be captured from above (gas station is upper left), (c) captured within a spherical worldlet, and (d) viewed in the worldlet at street level. | ||
Methods
General description
The experiment was designed to test whether guidebooks of worldlets are better for wayfinding than guidebooks of text and images, and if so, why are they better. A standard within-subject randomized design was used. Training began by reading subjects a series of instructions and teaching them how to operate the user interface in a practice three block by three block virtual city. Next, subjects were allowed to spend unlimited time in this city becoming familiar with the controls and the on-line guidebooks. Each subject was then asked to find their way to a brightly colored goal kiosk, via one landmark, in three practice cities, each five blocks by five blocks. In one city, the guidebook represented each landmark with a paragraph of text, in another city the landmarks were represented as 2D thumbnail images, and in a third city the landmarks were represented in a spherical worldlet. The guidebooks only contained landmark information; subjects were given no procedural or survey information. Although the thumbnail and worldlet guidebook had the same appearance, as shown in Figure 4, the worldlets in the worldlet guidebook could be explored and manipulated.
 | ||
| Figure 4. The image and worldlet guidebook looked like this, however, subjects were able to interactively explore the worldlets in the worldlet guidebook. | ||
|
Parameter |
Constant value |
Comments |
|
City dimensions |
10x10 blocks |
100 total blocks |
|
Building lots per block |
20 on perimeter of block |
building footprint varies |
|
Distance from start to goal |
1200 meters |
past 100 12 meter-wide lots |
|
Landmarks per city |
9, including goal kiosk |
ordered in guidebooks |
|
Distance between landmarks |
1.5 blocks |
+/- 0.25 block |
|
Travel speed |
5 meters/second |
slow driving speed |
|
Types of landmarks |
8 |
1 of each kind in each city |
|
Turns required to reach goal |
5 |
left and right turns |
|
Radius of information |
~20 meters |
see city design section |
|
Landmark positions |
3 on corner, 5 midblock |
goal is midblock |
|
Goal building |
yellow/red striped kiosk |
6 sided, viewpoint invariant |
| Table 1. Although the arrangement of buildings, landmarks, and routes were different in each city, their basic structure in terms of city design and landmark layout was kept constant to allow for controlled comparision. Subjects moved at a fixed speed in all cities. |
After completing the practice tasks, the experiment began and subjects were asked to find their way to the goal kiosk via eight ordered landmarks in three ten block by ten block virtual cities. Performance in these three cities was timed and the subject's location, orientation, and actions were recorded at one second intervals. Subjects visited the test cities in a random order to counterbalance possible learning effects. Each of the cities and landmarks were different and unique.
Before the computer portion of the experiment, subjects filled out a brief questionnaire on their prior experience with computers. After the experiment subjects answered written questions about the strategies they used while finding their way, and how difficult they found the task using each of the guidebooks. Subjects also completed spatial and verbal neuropsychological tests during a separate session.
Constants
The major independent variable in this experiment was the type of guidebook used (text, image, worldlet). Parameters concerned with city design and landmark layout, as described in Table 1, were held constant.
City design
Our primary goal in designing the virtual cities was to preserve as many elements of a real city as possible. Toward this goal we developed a pseudo-random city generator that produced cities based on a regular street grid with pavement roads and sidewalks between the blocks. Each block contained up to twenty buildings, side-by-side around the block perimeter. Using a cache of 250 building designs, buildings were randomly selected and placed on city blocks. Many non-landmark buildings were repeated between and within the cities. Rendering requirements were reduced by programming buildings to make themselves invisible when farther than three blocks from the current viewpoint. To prevent subjects from seeing buildings turning on and off in the distance, we added fog to the environment.
Cities contained parks, parking lots, and other civic features but did not contain cars or street signs. The landmarks were placed so that a subject could not shortcut the route and would never have to make an exhaustive search; i.e. as long as they carefully looked down each possible path for familiar landmarks and landmark context, they could always determine in which direction to proceed. No landmarks were located within one block of the perimeter wall that surrounded each city.
Radius-of-information
Radius-of-information was the most difficult parameter to make constant across the three guidebooks. Given that text, 2D images, and worldlets are different representations, they do not convey an equivalent quantity and quality of landmark information. We determined, while building the guidebooks for the pilot study, that using a radius of twenty meters produced the most nearly equivalent set of guidebooks. For the text guidebook this meant describing in words the landmark, the building or structure directly across the street, the building on each side, and whether the landmark was on a corner or not. Thus our textual description of a landmark with a twenty meter radius read as follows:
Citgo Gas Station. Citgo's red gas pumps are at a corner location. Next door is the Cafe 360 in a beige colored building, and across the street is the Lumbini Restaurant in a red brick building.
For the image guidebook, a twenty meter radius meant positioning the camera across the street from the landmark so that the captured thumbnail image would contain the buildings or structures on the left and right of the landmark. For the worldlet guidebook, setting the information radius simply meant setting the yon clip plane to cut away 3D shapes further away than twenty meters while capturing a spherical worldlet. Image and worldlet camera locations were selected so as not to suggest a direction of approach to the landmark.
 | ||
| Figure 5. The main city window. | ||
Hardware and software design
The experiment was conducted using a standard 19 inch Silicon Graphics monitor. Stereo glasses were not used. A VRML browser user interface was modified for the experiment. A main city window displayed the city. Subjects used keyboard arrow keys to move forward and backward a fixed distance on each key press, and to turn left and right by a fixed angle on each key press. In the worldlet guidebook, subjects used the arrow keys in the same manner to move around in the worldlet. Collision detection prevented subjects from passing through buildings and other objects in the city.
Subjects pushed a Start button before starting, a Landmark button each time a landmark was reached, and a Stop button upon reaching the goal kiosk. Subjects pushed a Guidebook button, located near the Start button, to display the guidebook. Subjects practiced operating all of these buttons in practice cities prior to beginning the experiment. The windows were designed so that when the guidebook (Figure 4) was open, the main city window (Figure 5) was completely occluded and no movement could be made.
Lessons learned from the pilot study
Our pilot study design and results are described in [Elvins97a]. From the pilot study we learned that landmarks cannot be more than two blocks apart or subjects frequently resort to an exhaustive search of the neighborhood. We also learned that some subjects will take much longer than other subjects to complete the task and that the task difficulty and length must be designed while keeping the slower wayfinders in mind.
Subject instructions
The following is a subset of the instructions read to the subjects. Instructions 3 and 4 were repeated before beginning each city.
1. The guidebook contains a series of landmarks that you probably want to follow, since traveling past these landmarks will lead you to the goal kiosk.
2. When you are at a landmark, you may have to walk as far as one or two blocks before you will be able to see the next landmark.
3. Your task is to locate the goal kiosk as quickly as possible. Go as fast as you can, but be careful to not get lost
4. Remember, you can look at the guidebook as often as you like
Subjects
Subjects were primarily University of California, San Diego students from a number of major departments. Ages ranged from 18 to 36, with a mean age of 24. Fourteen males and twelve females completed the experiment. Results from four other subjects had to be excluded from our data because the subjects became lost in one or more of the cities. All subjects were computer literate, but had varying degrees of experience with virtual environments.
Neuropsychological tests
To provide an independent measure of a subset of the subjects' cognitive abilities, subjects were tested in a separate session, using two standardized subtests from the Wechsler Adult Intelligent Scale - Revised (WAIS-R) [Wechsler81].
The Vocabulary subtest, comprising part of the WAIS-R Verbal subtests, was used to assess the subject's verbal ability. Performance was scored according to standardized procedures based on the subject's degree of familiarity with a list of up to 35 words and their elegance of expression [Wechsler81].
The second test was the Block Design subtest comprising part of the WAIS-R Performance subtests. The test was used to assess the subjects' constructional-spatial ability, and was administered in the standardized manner [Wechsler81].
Analysis
A one-way repeated measures analysis of variance (ANOVA) was performed for each of the dependent variables and the overall times and distances. The within-subjects variable was the landmark description type with three levels: text, image, and worldlet. Post-hoc analyses were done using the Scheffé test for differences in sample means. Correlation analysis was performed across the scores of the neuropsychological tests and the scores of the wayfinding tests. We adopted a significance level of 0.05 on all analyses unless otherwise noted.
Results
Our primary result was that people spend more time consulting the worldlet guidebook than the other guidebooks, but require less time to reach the goal when using the worldlet guidebook. The following specific findings tell us more about the component activities that benefitted from worldlet use.
Time and distance measures
Figures 6 through 9 show time and distance measures where the independent variable (type of guidebook) is displayed as white, grey, and black bars along with the standard error of the mean (SEM). Figure 6 shows the mean overall time and distance required to reach the goal kiosk. Figure 7 breaks the overall time into its components. Figure 8 gives the forward and backtracking distance components. Figure 9 shows the mean number of times that each type of guidebook was opened. Figure 10 diagrams the subjects' scores on the Wechsler neuropsychological tests.
Analysis of variance followed by Scheffé post hoc tests were performed for the different measures. Table 2 summarizes these results.
(a) (b) | ||
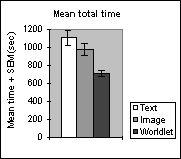
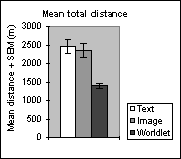
| Figure 6. (a) Mean total time. The overall time spent traveling to the goal was significantly less using the worldlet guidebook than when using the text (F(1,24)=9.89, p<0.01) or image (F(1,24)=4.63, p<0.01) guidebooks. (b) Mean total distance. The overall distance traveled using the worldlet guidebook was significantly less than the distance traveled using the text (F(1,24)=11.41, p<0.01) or image (F(1,24)=8.93, p<0.01) guidebooks. | ||
| ||
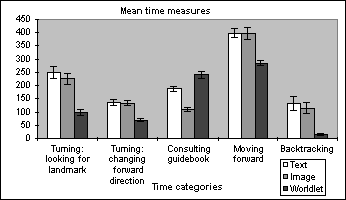
| Figure 7. Turning: looking for landmark is time spent standing in one location. Turning: changing heading is time spent changing forward direction. Consulting guidebook is time spent with the guidebook on screen. Moving forward is time spent traveling over new ground. Backtracking is time spent retreating. Note that time spent consulting the worldlet guidebook is significantly greater than time spent consulting the text or image guidebook. Also note that time backtracking is near zero when using the worldlet guidebook. | ||
| ||
| Figure 8. The mean distance moving forward while using the worldlet guidebook is significantly less than the forward distance covered while using the text or image guidebook. Backtracking distance is almost non-existent for the worldlet guidebook task. | ||
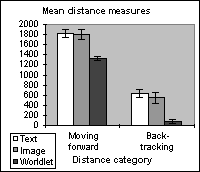
| ||
| Figure 9. Subjects opened the text and image guidebooks on average 15-16 times while seeking the eight landmarks enroute to the goal kiosk. The worldlet guidebook was opened 11 times on average. | ||
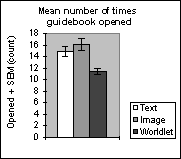
| ||
| Figure 10. Z transformed spatial and verbal scores from the neuropsychological tests. Before applying the z transform, the mean spatial test score was 45, and mean verbal test score was 55. | ||
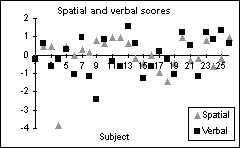
(a)
(b)
(c) | ||
| Figure 11. Street plots. In these plots line thickness and brightness indicates the number of times that a street was traversed. In (a) and (b) the 26 subjects traversed some streets 47 times indicating backtracking. (a) and (b) also exhibit circuitous trails. In (c) very little backtracking occurred, and circuitous trails are minimal. | ||
Street plots
Figure 11 shows plots of the streets traversed by the 26 subjects in the three test cities. The thickness and brightness of each street line indicate the total number of times that the street was traversed. For example, wider brighter streets indicate heavily used avenues. Backtracking can increase the number of street traversals beyond the expected minimum of 26. The starting point and goal kiosk are indicated on each plot, and landmarks enroute to the goal are marked with a star (I).
|
Post hoc comparisons (Scheffe F-test) | ||||||
|
Time |
ANOVA |
text vs. image |
text vs. worldlet |
image vs. worldlet | ||
|
consulting guidebook |
55.59 * p<0.0001 |
19.66 * p<0.001 |
8.84 * p<0.01 |
54.88 * p<0.011 | ||
|
looking for landmark |
21.61* p<0.0001 |
0.47 |
18.69 * p<0.001 |
13.25 * p<0.01 | ||
|
changing heading |
17.36 * p<0.0001 |
0.02 |
13.53 * p<0.01 |
12.49 * p<0.01 | ||
|
moving forward |
16.02 * p<0.0001 |
0.003 |
12.20 * p<0.01 |
11.83 * p<0.01 | ||
|
back-tracking |
9.55 * p<0.0003 |
0.22 |
8.26 * p<0.01 |
5.86 * p<0.01 | ||
|
overall |
10.34 * p<0.0002 |
0.98 |
9.89 * p<0.01 |
4.63 * p<0.01 | ||
|
Distance |
||||||
|
moving forward |
15.33 * p<0.0001 |
0.05 |
12.23 * p<0.01 |
10.72 * p<0.01 | ||
|
back-tracking |
10.19 * p<0.0002 |
0.23 |
8.84 * p<0.01 |
6.21 * p<0.01 | ||
|
overall |
13.65 * p<0.0001 |
0.15 |
11.41 * p<0.01 |
8.93 * p<0.01 | ||
|
Guidebook |
||||||
|
opened |
15.27 * p<0.0001 |
1.04 |
7.59 * p<0.01 |
14.26 * p<0.001 | ||
| Table 2. Our ANOVA indicated that there were significant differences between all the sample means and post hoc analysis was warranted. Post hoc (Scheffe) analysis indicated that, for all dependent variables, there were significant differences in the sample means of the text versus worldlet performance, and thumbnail versus worldlet performance. Performance using the text versus image guidebooks was not significantly different except that time spent consulting the text guidebook was significantly greater than time spent consulting the image guidebook. In each table cell, the upper number is the F value, and the lower number is the p value. Asterisk indicates significance p<0.05. Time and distance measures are explained in the captions for Figures 6-9. |
Subjective measures
As part of the written questionnaire administered after the experiment, subjects were asked how difficult the search task was using each of the different types of guidebooks. Responses were scattered, however, a clear trend in favor of the worldlet guidebook was evident.
|
Text |
image |
worldlet | |
|
Very easy |
0 |
2 |
11 |
|
Easy |
10 |
8 |
9 |
|
Doable |
10 |
8 |
6 |
|
Difficult |
5 |
7 |
0 |
|
Very difficult |
1 |
1 |
0 |
|
Median |
Doable |
Doable |
Easy |
| Table 3. Subjects were asked to rate the difficulty of the search task using the three different types of guidebooks. |
Correlation analysis
One surprising finding was a high inverse correlation (-0.77, p=0.01) between spatial skills and the time spent consulting the text guidebook. Subjects with good spatial abilities seemed able to form a mental picture of a landmark on the basis of textual description more quickly than subjects with lower spatial abilities. This is not the case for image and worldlet guidebooks.
We also expected to find a negative correlation between spatial skills and overall travel time in the thumbnail and worldlet guidebook cities. The data did not support this, nor did they support another of our hypotheses that there would be a positive correlation between verbal skills and the performance in the text guidebook city. Verbal skills made no difference in overall wayfinding time.
Additional observations
Many subjects said that the tasks were harder than they had imagined, and afterwards several said that they felt tired. No subjects complained of motion sickness. Most subjects required seventy minutes or more to finish all aspects of the computer-based part of the experiment.
We observed subjects to use three general types of strategies while deciding what direction to go from a street intersection:
1. Look down each street from many viewpoints within the intersection, until a landmark or landmark context is seen.
2. Look down each street and if nothing looks familiar, search exhaustively in each direction until the next landmark is found.
3. Look down each street and if nothing looks familiar, try going one half block in each direction and look again.
Subjects using strategy #1 seemed to find their way more quickly and with less backtracking than subjects who used strategies #2 and #3. Another strategy, described by some subjects on their written questionnaire, involved viewing a landmark in the worldlet guidebook from many distant vantage points in the hopes that one of the vantage points would be similar to the direction from which they would actually approach the landmark in the city. We observed that some subjects often forgot what it was they were looking for, and so had to open the guidebook momentarily to remind themselves.
Not surprisingly, landmarks with signs such as "Grocery Store" and landmarks painted with more highly saturated colors seemed easier to find than other types of landmarks. Also, after passing all the landmarks, several subjects exclaimed that they had lost all sense of direction within the world.
A final unexpected result is that there were many similarities between the text and image guidebooks. The text and image guidebooks were only significantly different in the time subjects spent consulting them. Considering that text and images represent landmarks in very different ways, we expected differences in time and distance measures.
Major findings
1. As we predicted, the total time spent traveling to the goal was significantly less using the worldlet guidebook than when using the text or image guidebooks.
2. Subjects spent significantly more time studying the worldlet guidebook than the text or image guidebook.
3. Increased worldlet study time was more than compensated for by a reduction in the time required to reach the goal. Using the worldlet guidebook, subjects traveled on average 55% faster than when using the text guidebook, and 38% faster than when using the image guidebook.
4. Increased worldlet study time also allowed subjects to move more directly to the goal and reduced backtracking time to almost zero. This is shown diagramatically in Figure 11 where Figures 11a and 11b show brighter wider streets than Figure 11c. Figure 11c also exhibits fewer detours and less wandering than Figures 11a and 11b.
We postulate that compared to the landmark knowledge gained from text and image guidebooks, the improved landmark knowledge built while consulting the worldlet guidebook enabled subjects to refer less frequently to the guidebook. This postulation is further supported by examining worldlet guidebook results:
• Subjects spent significantly more time studying the worldlet guidebook than the other types of guidebooks
• When using the worldlet guidebook, subjects traveled faster, more directly, and with more skill, to the goal kiosk
• Subjects' median rating for the difficulty of the search task was 'Easy' when using the worldlet guidebook.
Conclusion
We know of no studies that have considered the comparative advantages of different types of guidebooks for wayfinding. Intuitively, one would predict that 3D thumbnails make better guidebooks for 3D worlds than do text and 2D thumbnail images, and indeed, this is what we found. We wanted, however, to identify the component activities in using guidebooks that most benefited from 3D elements. Perhaps of greatest interest was our finding that worldlets enabled subjects to find their way in complex environments with almost no backtracking. By spending more time studying the worldlets in their guidebooks, they spent less time looking around, re-orienting themselves, conducting exhaustive searches, and performing similar time-wasting activities. We must be cautious, however, in what we conclude since worldlets contain more information than text or 2D thumbnail images. To control for this difference in information content, more experiments are necessary.
Future work
We would like to investigate the comparative advantages of worldlet guidebooks for wayfinding tasks in corresponding virtual and real world environments (both urban and rural). We are also considering an experiment to evaluate tandem use of traditional 2D maps and landmark guidebooks.
Acknowledgements
Our appreciation goes to Planet 9 Studios (http://www.planet9.com) for the use of their city building textures. Thanks to John Moreland and Mike Bailey for technical assistance on this project, and thanks to Suzi Feeney for collaborating in the pilot study design. UCSD librarian Debbie Cox and her staff were invaluable in locating references. Thanks also to John Helly and Reagan Moore for their support. San Diego Supercomputer Center is funded by NSF, grant ASC 8902825, the University of California, the State of California, and industrial partners.References
-
- Appleyard, D.A., "Why buildings are known," Environment and Behavior, 1969, 1, 131-156.
- Art+Com, "The cybercity Berlin project", http://www.artcom.de/projects
- Darken, R. P., and Sibert, J. L., "Wayfinding strategies and behaviors in large virtual worlds," in Proceedings of the ACM CHI 96 Conference, Vancouver, BC., April, 1996, 142-149.
- Downs, R. J., and Stea, D., "Cognitive maps and spatial behavior," in Image and Environment, Chicago: Aldine Publishing Company, 1973, 8-26.
- Elvins, T.T., Nadeau, D.R., Kirsh, D., "Worldlets - 3D thumbnails for wayfinding in virtual environments,"in Proceedings of the ACM User Interface Software and Technology Symposium, Banff, Canada, October, 1997.
- Elvins, T.T., "Wayfinding in layered information worlds," Short paper in Proceedings of the CODATA Euro-American Workshop on Data and Information Visualization, Paris, France, June, 1997, 6-7.
- Goldin, S.E., Thorndyke, P.W., "Simulating navigation for spatial knowledge acquisition," Human Factors, 1982, 24 (4), 457-471.
- Liggett, R., Friedman, S. and Jepson, W., "Interactive design/decision making in a virtual urban world: visual simulation and GIS," in Proceedings of the 1995 ESRI User Conference, Environmental Systems Research, July, 1995 http://www.esri.com/base/common /userconf/proc95
- Lynch, K., The Image of the City, M.I.T. Press, 1960.
- Passini, R., Wayfinding in Architecture, Van Nostrand Reinhold, NY, second edition, 1992.
- Peponis, J., Zimring, C., and Choi, Y.K., "Finding the Building in Wayfinding," Environment and Behavior, 1990, 22 (5), 555-590.
- Presson, C.C., Hazelrigg, M.D., "Building Spatial Representations Through Primary and Secondary Learning," Journal of Experimental Psychology: Learning, Memory and Cognition, 1984, 10, 716-222.
- Satalich, G. A., Navigation and Wayfinding in Virtual Reality: Finding the Proper Tools and Cues to Enhance Navigational Awareness., Masters Thesis, Department of Computer Science, University of Washington, 1995. http://www.hitl.washington.edu/publications/
- University College London Center for Advanced Spatial Analysis, "Virtual London: a proposal," http://www.geog.ucl.ac.uk/casa/vl.html
- Wechsler, D., WAIS-R Manual, The Psychological Corporation, Harcourt Brace Jovanovich, Inc., 1981.
- Wickens, C., and Baker, P., "Cognitive Issues in Virtual Reality," Chapter 13 in Mental Models and Human-computer Interaction, Editors Woodrow Barfield and Thomas Furness III, Oxford University Press, 1995, 514-541.
- Witmer, G.G., Bailey, J.H., Knerr, B.W., Parsons, K.C., "Virtual spaces and real world places: transfer of route knowledge," Int. J. Human-computer Studies, 45, 1996, 413-428.
- Appleyard, D.A., "Why buildings are known," Environment and Behavior, 1969, 1, 131-156.
Other Articles